
ACL Trends Visualization by Wanxiang Che
With ACL becoming virtual this year, I unfortunately spent less time networking and catching up with colleagues, but as a silver lining I watched many more talks than I usually do. I decided to share the notes I took and discuss some overall trends. The list is not exhaustive, and is based on my research interests. I recommend also checking out the best papers.
EDITOR’S NOTE: TOPBOTS has summarized the research papers that received Best Paper Awards at ACL 2020.
Overall trends over the years
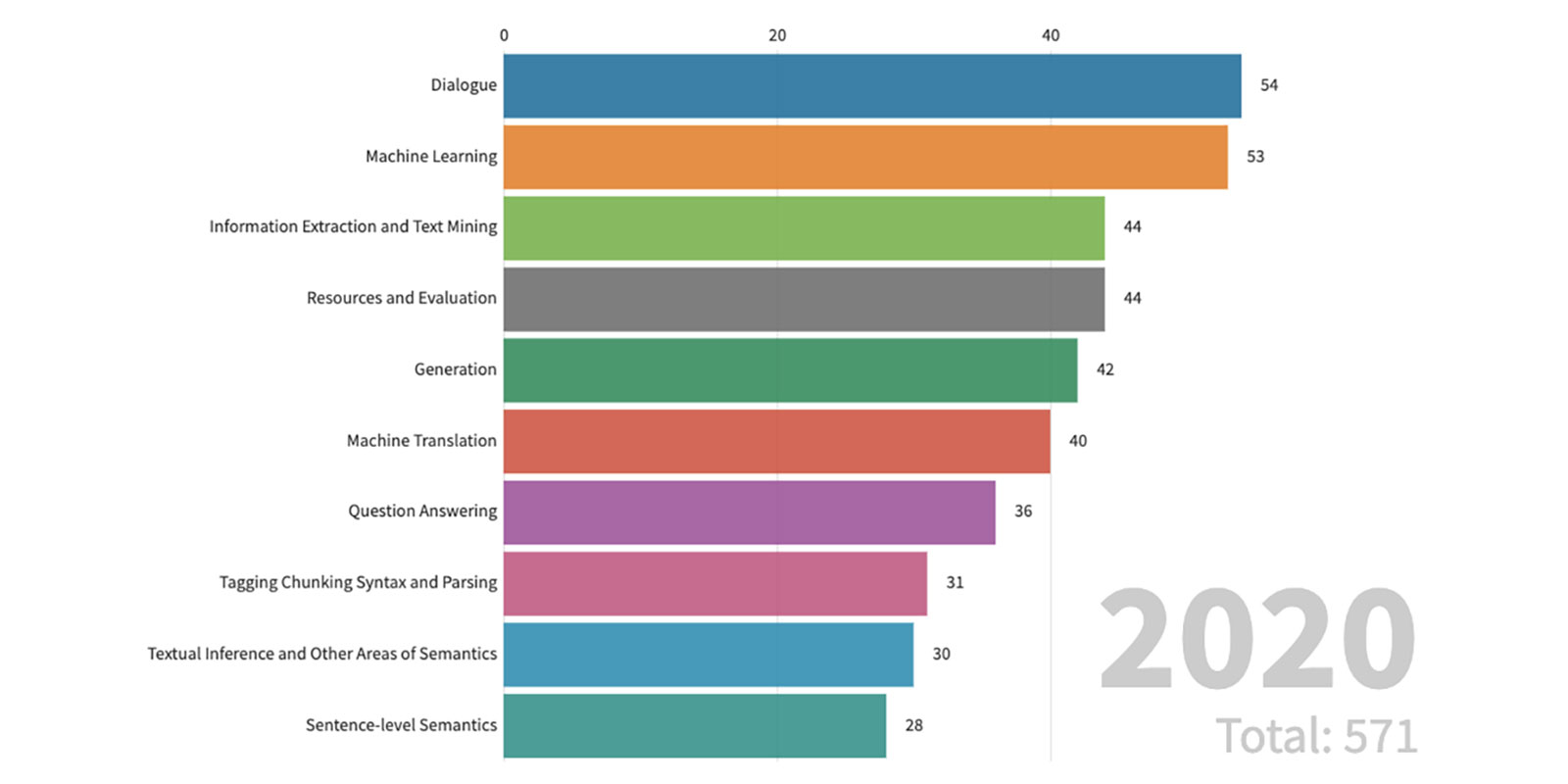
Before I start discussing trends in the talks I watched (which obviously suffer from sampling bias), let’s look at some overall statistics from the ACL blog. This year, the tracks that received the highest number of submissions were Machine Learning for NLP, Dialogue and Interactive Systems, Machine Translation, Information Extraction, NLP applications, and Generation.
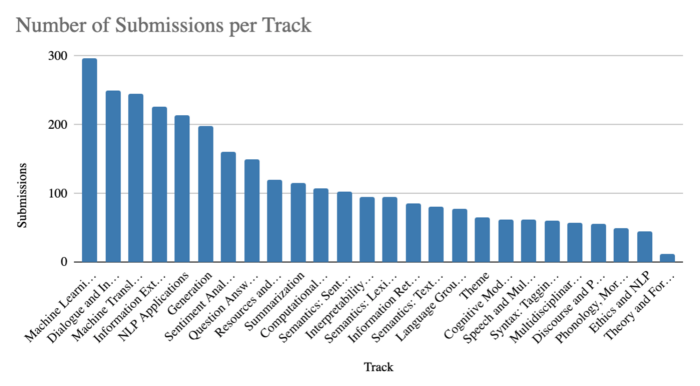
How does it compare to previous years? This excellent visualization by Wanxiang Che shows the number of papers in each track since 2010:
Overall, there is a trend of moving from lower-level to higher-level tasks, i.e. from syntax through word-level semantics, sentence-level semantics, discourse, to dialogue. The “machine learning” track is growing steadily as more papers present general-purpose models which are evaluated on multiple tasks.
Do you find this in-depth content on NLP research to be useful? Subscribe below to be updated when we release new relevant content.
Trends at ACL 2020
Less “I fine-tuned BERT on task X and it improved the performance on benchmark Y” papers
There is a reoccurring pattern in NLP research of (1) introducing a new architecture / model; (2) publishing low hanging fruit by improving the architecture / model or applying it to various tasks; (3) publishing analysis papers that show its weaknesses; (4) publishing new datasets. I’d say we are currently between 2 and 3, though some things are happening in parallel. Again, I might be basing this conclusion off of my choice of papers, which has largely filtered out this type of papers. So a softer conclusion would be “there are enough papers at ACL 2020 that are not of this type”.
Shifting away from huge labeled datasets
In the last 2 years we’ve seen a shift towards pre-training in a self-supervised manner on unlabeled texts and then fine-tuning with (potentially) smaller task-specific datasets. In this conference, many papers were focused on training models with less supervision. Here are some alternatives to training on huge datasets, along with example papers:
Unsupervised: Yadav et al. propose a retrieval-based QA approach that iteratively refines the query to a KB to retrieve evidence for answering a certain question. Tamborrino et al. achieve impressive results on commonsense multiple choice tasks by computing a plausibility score for each answer candidate using a masked LM.
Data augmentation: Fabbri et al. propose an approach to automatically generate (context, question, answer) triplets to train a QA model. They retrieve contexts that are similar to those in the original dataset, generate yes/no and templated WH questions for these contexts, and train the model on the synthetic triplets. Jacob Andreas proposes replacing rare phrases with a more frequent phrase that appears in similar contexts in order to improve compositional generalization in neural networks. Asai and Hajishirzi augment QA training data with synthetic examples that are logically derived from the original training data, to enforce symmetry and transitivity consistency.
Meta learning: Yu et al. use meta learning to transfer knowledge for hypernymy detection from high-resource to low-resource languages.
Active learning: Li et al. developed an efficient annotation framework for coreference resolution that selects the most valuable samples to annotate through active learning.
Language models is not all you need — retrieval is back
We already knew that knowledge from language models is lacking and inaccurate. In this conference, papers from Kassner and Schütze and Allyson Ettinger showed that LMs are insensitive to negation and are easily confused by misprimed probes or related but incorrect answers. Various solutions are currently employed:
Retrieval: Two of the invited talks at the Repl4NLP workshop mentioned retrieval-augmented LMs. Kristina Toutanova talked about Google’s REALM, and about augmenting LMs with knowledge about entities (e.g. here, and here). Mike Lewis talked about the nearest neighbor LM that improves the prediction of factual knowledge, and Facebook’s RAG model that combines a generator with a retrieval component.
Using external KBs: this has been commonly done for several years now. Guan et al. enhance GPT-2 with knowledge from commonsense KBs for commonsense tasks. Wu et al. used such KBs for dialogue generation.
Enhancing LMs with new abilities: Zhou et al. trained a LM to capture temporal knowledge (e.g. on the frequency and duration of events) using training instances obtained through information extraction with patterns and SRL. Geva and Gupta inject numerical skills into BERT by fine-tuning it on numerical data generated using templates and textual data that requires reasoning over numbers.
Explainable NLP
It seems that this year looking at attention weights has gone out of fashion and instead the focus is on generating textual rationales, preferably ones that are faithful — i.e. reflect the discriminative model’s decision. Kumar and Talukdar predict faithful explanations for NLI by generating candidate explanations for each label, and using them to predict the label. Jain et al. develop a faithful explanation model that relies on post-hoc explanation methods (which are not necessarily faithful) and heuristics to generate training data. To evaluate explanation models, Hase and Bansal propose to measure users’ ability to predict model behavior with and without a given explanation.
Reflecting on current achievements, limitations, and thoughts about the future of NLP
ACL had a theme track this year, with the theme “Taking Stock of Where We’ve Been and Where We’re Going”, that produced some thought provoking papers. Other insights came from the invited speakers and from papers in other tracks. Here are several of the conclusions.
We are solving datasets, not tasks. This claim comes up over and over again over the last few years, but yet, our main paradigm is to train huge models and evaluate them on crowdsourced test sets that are too similar to our training sets. The honorable mention theme paper by Tal Linzen argued we train models on huge amounts of data that may not learn anything from the amounts of data that are available to people, and that these models find statistical patterns in the data that humans might consider irrelevant. He suggested that moving forward, we should standardize moderately sized pre-training corpora, use expert-created evaluation sets, and reward successful few-shot learning.
Kathy McKeown’s excellent keynote also touched upon this point and added that leaderboards are not always helpful to advancing the field. Benchmarks typically capture the head of the distribution, whereas we need to be looking at the tail. In addition, it’s difficult to analyze the progress on specific tasks with general-purpose models (like LMs). In her Lifetime Achievement Award interview, Bonnie Webber stressed the need to look at the data and analyze the model errors. Even something as trivial as looking at both precision and recall instead of only the aggregated F1 score can help in understanding the model’s weaknesses and strengths.
There are inherent limitations in current models and data. Bonnie also said that neural nets are capable of solving tasks that don’t require deep understanding, but that a more challenging goal is to recognize implicit implications and world knowledge. Several papers, in addition to the ones mentioned above, revealed limitations in current models: for example, both Yanaka et al. and Goodwin et al. indicated that neural NLU models lack systematicity and are hardly capable of generalizing learned semantic phenomena. The best theme paper by Emily Bender and Alexander Koller argued that it’s impossible to learn meaning from form alone. Similar claims were made in the preprint by Bisk et al. that advocates using multiple modalities to learn meaning.
We need to move away from classification tasks. We’ve seen multiple evidence over the recent years that classification and multiple choice tasks are easy to game and that models can achieve good accuracy by learning shallow data-specific patterns. On the other hand, generation tasks are difficult to evaluate, with human evaluation currently being the only informative metric, but an expensive one. As an alternative to classification, Chen et al. converted the NLI task from 3-way classification to a softer probabilistic task that aims at answering the question “how likely is a hypothesis to be true given the premise?”. Pavlick and Kwiatkowski further show that even humans disagree about the entailment label of certain sentence-pairs, and that in some cases different interpretations can justify different labels (and averaging annotations may lead to errors).
We need to learn to handle ambiguity and uncertainty. Ellie Pavlick’s talk at Repl4NLP discussed the challenge in clearly defining the goal in semantics research. Naively translating semantic theories into NLI-style tasks is doomed to failure because language is situated and grounded in broader context. Guy Emerson defined the desired properties of distributional semantics, one of which was capturing uncertainty. Feng et al. designed dialog response task and model that include a “none of the above” response. Finally, Trott et al. pointed out that while semantic tasks are concerned with identifying that two utterances have the same meaning, it’s also important to identify how difference in phrasing impacts meaning.
Discussions about ethics (it’s complicated)
I think it’s quite remarkable how in just a few years, ethics in NLP turned from a niche topic studied by a few dedicated researchers to a track in ACL and a consideration for all of us submitting papers to other tracks. In fact, as a community we’ve now switched to criticizing papers that aim to shed light on an important fairness issue when they fail to address other ethical considerations (I hope this paper will be revised rather than withdrawn!).
I highly recommend watching Rachael Tatman’s insightful “What I Won’t Build” keynote in the WiNLP workshop. Rachael specified which types of systems she personally wouldn’t help building (surveillance systems, applications that deceive users that interact with them, and social category detectors). She provided the following list of questions that researchers can use to decide whether a system should be built or not:
- Who benefits from the system?
- Who could be harmed by it?
- Can users choose to opt out?
- Does the system enforce or worsen systemic inequalities?
- Is it generally bettering the world?
Leins et al. brought up many interesting but yet unanswered ethical questions such as what is ethical research in NLP, who determines that and how? Who is responsible for the prediction of models? Should ACL attempt to position itself as an ethical gatekeeper? One of the issues discussed in the paper was that of dual use: a model that can be used for both good and bad purposes. In fact, during the conference, a Twitter debate (unfortunately led by an anonymous account) was held with respect to the best demo paper by Li et al., about an impressive multimedia knowledge extraction system, on that ground.
Miscellaneous
Here are some other papers that I liked that don’t belong to any of the above categories. Cocos and Callison-Burch created a large resource of sense-tagged sentences in which sense is indicated through paraphrases, e.g. “bug-microphone”. Zhang et al. suggested an approach to trace the provenance of text, including its author and influences from other sources. Chakrabarty et al. addressed translating non-sarcastic sentences to sarcastic ones, with a model built based on insightful observations about sarcasm. Wolfson et al. introduced the standalone task of question understanding, which follows the human way to answer complex questions by breaking it to simpler questions. Gonen et al. proposed a very intuitive and interpretable method to measure the change in words’ meanings by looking at their distributional nearest neighbors. Anastasopoulos and Neubig show that while it’s best practice to use English as the hub for cross-lingual embedding learning, it’s often suboptimal, and suggest general guidelines for selecting a better hub. Finally, Zhang et al. crowdsourced explanations for the Winograd Schema Challenge and analyzed the type of knowledge needed for solving the task and the level of success of existing models on each category.
Conclusion and additional thoughts
The papers and keynotes strengthened my feeling that despite the tremendous progress of the last couple of years, we’re not quite in the right direction yet, nor do we have a very feasible way forward. I think that the theme track was a positive change and a great way to encourage papers that don’t focus on small immediate gains but looking at the big picture.
I liked being able to watch so many talks on my own time (and with my preferred speed), but I did miss the interaction, and I don’t think that zoom meetings and chat rooms with participants across different time zones are a satisfactory substitute. I really hope that future conferences after the pandemic will be held in-person again, but hopefully while also allowing for remote participants in reduced registration fees. Hope to see y’all next year queuing for a bad coffee!
This article was originally published on Medium and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more NLP research updates.
We’ll let you know when we release more summary articles like this one.
Leave a Reply
You must be logged in to post a comment.