
With a record high of 9034 research papers submitted to AAAI 2021 and an acceptance rate of 21%, a total of 1692 papers were presented at the conference. As usual, the Outstanding and Distinguished Papers awards were given to the papers exemplifying the highest standards in technical contribution and exposition. Of course, there were many more papers presented at the conference that are worth your attention.
To help you stay aware of the prominent AI research breakthroughs, we’ve summarized some of the most interesting AAAI 2021 research papers introduced by Google, Alibaba, Baidu, and other leading research teams.
If you’d like to skip around, here are the papers we featured:
- Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
- TabNet: Attentive Interpretable Tabular Learning
- Train a One-Million-Way Instance Classifier for Unsupervised Visual Representation Learning
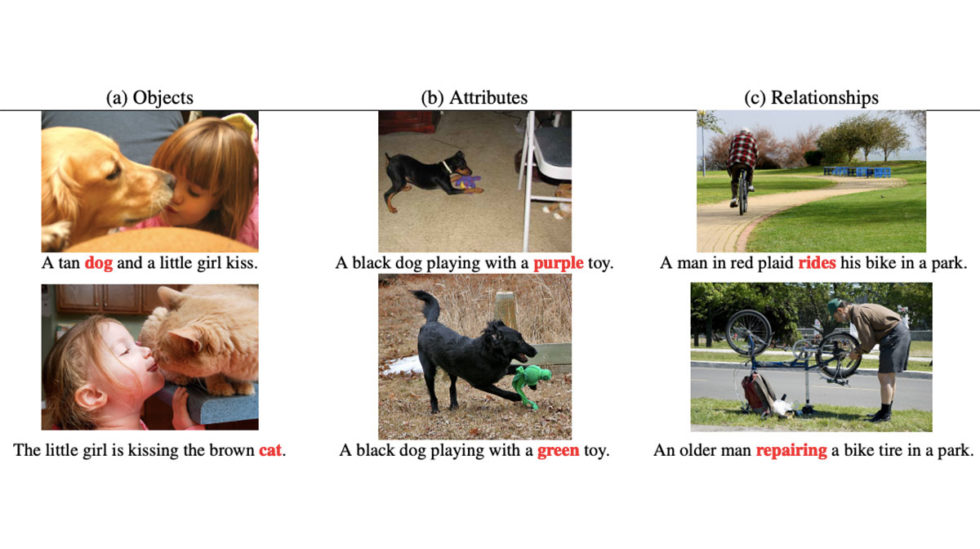
- ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
- Reinforced Imitative Graph Representation Learning for Mobile User Profiling: An Adversarial Training Perspective
If this in-depth educational content is useful for you, subscribe to our AI research mailing list to be alerted when we release new material.
Top AAAI 2021 Research Papers
1. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting, by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang
Original Abstract
Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, such as quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a ProbSparse Self-attention mechanism, which achieves O(L log L) in time complexity and memory usage, and has comparable performance on sequences’ dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.
Our Summary
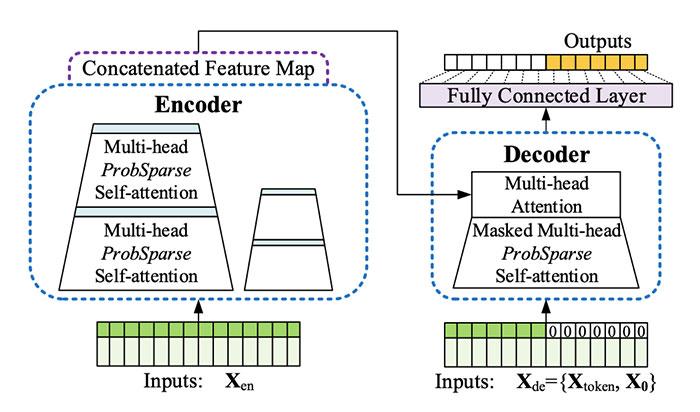
The current Transformer architectures are inefficient for long sequence time-series forecasting (LSTF), where a model needs to learn long-range input-output dependencies and also to offer inference speeds feasible for predicting more steps into the future (e.g., 480 points for hourly temperature records over 20 days). To make the architecture feasible for long sequential inputs, the authors proposed the ProbSparse Self-attention mechanism with O(L log L) complexity rather than O(L2) complexity, where L is the length of the sequence. A self-distillation method is proposed to scale the network efficiently for better accuracy, with O((2 − ε)L log L) complexity in place of the O(J · L2) complexity of a regular Transformer, where J is the number of transformer layers. A generative-style decoder is adapted to increase inference speeds compared to a step-by-step prediction of every point in the output. The proposed method is shown to perform better than existing methods in five real-world datasets for tasks including predicting ETT (Electricity Transformer Temperature), ECL (Electricity Consuming Load), and Weather.
What’s the core idea of this paper?
- ProbSparse Self-attention is proposed to take advantage of the sparsity or long-tail distribution of self-attention probabilities where only a few key-query attention weights drive the majority of the computation. ProbSparse achieves O(L log L) complexity, improving on O(L2).
- To scale the model by stacking transformer layers, the authors proposed a self-distillation technique using convolution and max-pooling operations so that the output size of the current layer, i.e. the input size of the next layer, is less than the input size of the current layer. This achieves O((2 − ε)L log L) complexity, compared to O(J · L2) for a general Transformer.
- Finally, to make the inference speeds scalable, a generative-style decoder is proposed to predict multiple points into the future in a single forward pass.
What’s the key achievement?
- The proposed method achieves superior performance on five real-world datasets for both univariate and multivariate long sequence time-series forecasting for tasks such as predicting ETT (Electricity Transformer Temperature), ECL (Electricity Consuming Load), and Weather.
What does the AI community think?
- The paper received the Outstanding Paper Award at AAAI 2021.
What are possible business applications?
- The proposed approach can be used to predict long sequences, including energy consumption, weather indicators, stock prices, etc.
Where can you get implementation code?
- The original PyTorch implementation of this paper is available on GitHub.
2. TabNet: Attentive Interpretable Tabular Learning, by Sercan O. Arik and Tomas Pfister
Original Abstract
We propose a novel high-performance and interpretable canonical deep tabular data learning architecture, TabNet. TabNet uses sequential attention to choose which features to reason from at each decision step, enabling interpretability and more efficient learning as the learning capacity is used for the most salient features. We demonstrate that TabNet outperforms other neural network and decision tree variants on a wide range of non-performance-saturated tabular datasets and yields interpretable feature attributions plus insights into the global model behavior. Finally, for the first time to our knowledge, we demonstrate self-supervised learning for tabular data, significantly improving performance with unsupervised representation learning when unlabeled data is abundant.
Our Summary
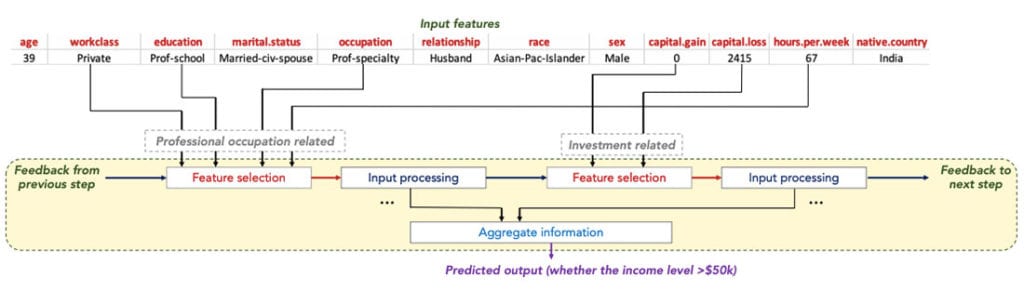
The Google Cloud AI team addresses the problem of applying deep neural networks for tabular data. While deep neural networks shine at automatic extraction of features and end-to-end learning, the lack of inductive bias for modeling the output decision boundaries that are prevalent in tabular data and the lack of interpretability limit the widespread adoption of deep neural networks for tabular data. The authors devise a sequential attention mechanism to select a subset of features to process at each step. This improves learning efficiency and interpretability by demonstrating the reasoning at each step, similarly to a decision tree. The feature selection is done for each instance to increase the model performance with more data. Unsupervised pre-training is also used to increase the performance with a task of predicting the masked values at different rows of different columns. The proposed TabNet model performs better than or on par with the standard methods for tabular data while eliminating the feature selection and feature engineering steps.
What’s the core idea of this paper?
- Devising a sequential attention mechanism that attends to only a subset of features while masking the others at each step before processing. This helps in efficient learning, as the model processes only salient features, and also with interpretability, as the reasoning steps could be analyzed based on the selected features.
- Unsupervised pre-training is shown to be useful in increasing the performance of the model by predicting masked values. This increased performance is out of reach for traditional ML models as they couldn’t be pre-trained in an unsupervised way.
What’s the key achievement?
- Experiments show that the proposed method, TabNet, performs as well as or better than established tabular data models on five real-world datasets while dealing with the interpretability concerns.
What are possible business applications?
- The approach can be useful for any applications working with tabular data, which is likely the most common data type in real-world machine learning applications.
Where can you get implementation code?
- The PyTorch implementation of this paper is available on GitHub.
3. Train a One-Million-Way Instance Classifier for Unsupervised Visual Representation Learning, by Yu Liu, Lianghua Huang, Pan Pan, Bin Wang, Yinghui Xu, Rong Jin
Original Abstract
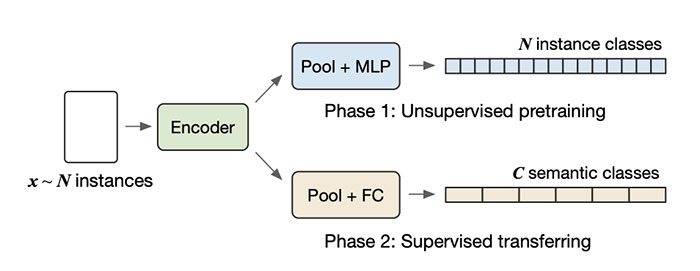
This paper presents a simple unsupervised visual representation learning method with a pretext task of discriminating all images in a dataset using a parametric, instance-level classifier. The overall framework is a replica of a supervised classification model, where semantic classes (e.g., dog, bird, and ship) are replaced by instance IDs. However, scaling up the classification task from thousands of semantic labels to millions of instance labels brings specific challenges including 1) the large-scale softmax computation; 2) the slow convergence due to the infrequent visiting of instance samples; and 3) the massive number of negative classes that can be noisy. This work presents several novel techniques to handle these difficulties. First, we introduce a hybrid parallel training framework to make large-scale training feasible. Second, we present a raw-feature initialization mechanism for classification weights, which we assume offers a contrastive prior for instance discrimination and can clearly speed up converge in our experiments. Finally, we propose to smooth the labels of a few hardest classes to avoid optimizing over very similar negative pairs. While being conceptually simple, our framework achieves competitive or superior performance compared to state-of-the-art unsupervised approaches, i.e., SimCLR, MoCoV2, and PIC under ImageNet linear evaluation protocol and on several downstream visual tasks, verifying that full instance classification is a strong pretraining technique for many semantic visual tasks.
Our Summary
Unsupervised representation learning has proved beneficial when we have a lot of data but few labels or when the task is not fully defined yet. The Alibaba research team addresses the problem of seamless unsupervised representation learning without the need to create negative pairs or new objective functions. The proposed method treats unsupervised representation learning as an instance-level supervised classification task, implying that all the images are assigned a unique class and an n-way classification model is trained, where n is the total number of images in the dataset. The authors also proposed novel techniques to deal with this large-scale classification task, including model parallel techniques for softmax computation, a technique to induce a contrastive prior, and a technique to smooth the ground truths of very similar negative classes. The method outperforms previous state-of-the-art models for unsupervised representation learning such as SimCLR and PIC.
What’s the core idea of this paper?
- Treating unsupervised representation learning as a large-scale instance-level classification task.
- Proposing novel techniques to handle large-scale classification tasks:
- introducing a hybrid parallel training framework for computing softmax operation on different devices;
- inducing a contrastive prior by presenting a raw-feature initialization mechanism for classification weights (i.e., the weights are initialized with the instance features that were extracted by running an inference epoch, where the model is a fixed random neural network with only batch-normalization layers being trained);
- smoothing the ground truths of very similar negative classes.
What’s the key achievement?
- This work devised a new, simple and efficient method for unsupervised representation learning without the use of negative pairs in class-level contrastive learning or large batch sizes to mitigate data leakage in instance-level contrastive learning.
What are possible business applications?
- This method could be used to cluster unlabeled images, which in turn facilitates similar image search and image tagging for image archival systems.
4. ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs, by Fei Yu, Jiji Tang, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang
Original Abstract
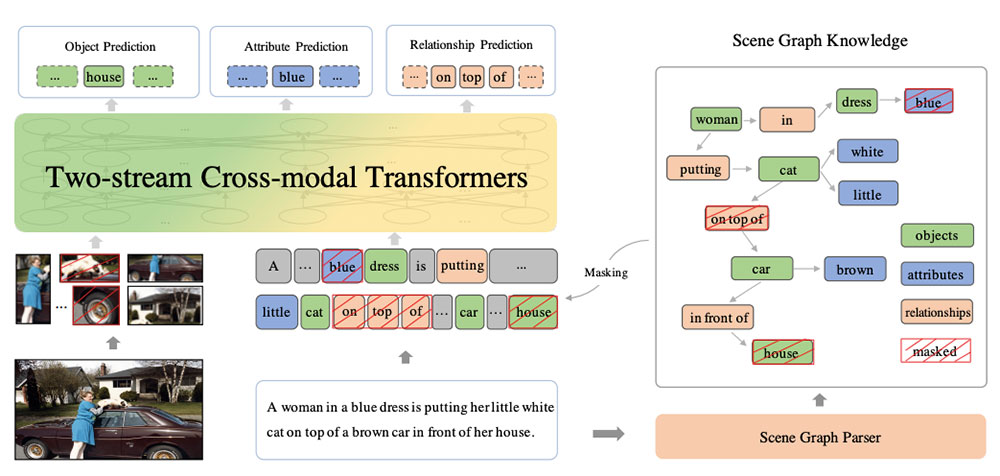
We propose a knowledge-enhanced approach, ERNIE-ViL, which incorporates structured knowledge obtained from scene graphs to learn joint representations of vision-language. ERNIE-ViL tries to build the detailed semantic connections (objects, attributes of objects and relationships between objects) across vision and language, which are essential to vision-language cross-modal tasks. Utilizing scene graphs of visual scenes, ERNIE-ViL constructs Scene Graph Prediction tasks, i.e., Object Prediction, Attribute Prediction and Relationship Prediction tasks in the pre-training phase. Specifically, these prediction tasks are implemented by predicting nodes of different types in the scene graph parsed from the sentence. Thus, ERNIE-ViL can learn the joint representations characterizing the alignments of the detailed semantics across vision and language. After pre-training on large scale image-text aligned datasets, we validate the effectiveness of ERNIE-ViL on 5 cross-modal downstream tasks. ERNIE-ViL achieves state-of-the-art performances on all these tasks and ranks the first place on the VCR leaderboard with an absolute improvement of 3.7%.
Our Summary
In this work, the Baidu research team tried to solve the alignment of semantic concepts in visual and linguistic space so that the models perform better at multi-modal tasks that require common sense physical reasoning (e.g., visual commonsense reasoning and visual question answering). The authors aimed at giving the models more structured knowledge about the scenes by pre-training the models to explicitly predict objects, their attributes, and object-object relations. With an image and a corresponding text, instead of masking and predicting random tokens in the text, the authors used scene-graph parsing and masked tokens that specifically represented objects, their attributes, and object-object relations. The model was pre-trained to predict the masked tokens in the text given an image. The introduced approach achieved state-of-the-art results in multi-modal datasets for text retrieval and image retrieval and also ranked first place on the VCR task leaderboard with an improvement of 3.7% compared to the next best solution.
What’s the core idea of this paper?
- Similar to BERT-like masked language modeling, image captioning models are trained to predict the masked tokens in an image caption given the image and other tokens. The core idea of this paper is to selectively mask the tokens rather than masking them randomly.
- In this approach, only the tokens that represent semantically rich entities such as objects, attributes of an object, and object-object relations are masked. This achieves better semantic alignment between text and images as all the learning focuses on semantically rich tokens in an image caption.
What’s the key achievement?
- Getting better grounding of the semantic textual entities in visual space.
- Achieving state-of-the-art results in image/text retrieval and visual common sense reasoning tasks.
What are future research areas?
- Incorporating scene graphs extracted from images into cross-modal pretraining.
- Using graph neural networks for representing images and text.
What are possible business applications?
- Better alignment of semantic concepts would give better results for image retrieval with text, image captioning, visual question answering, and forecasting future actions.
5. Reinforced Imitative Graph Representation Learning for Mobile User Profiling: An Adversarial Training Perspective, by Dongjie Wang, Pengyang Wang, Kunpeng Liu, Yuanchun Zhou, Charles Hughes, Yanjie Fu
Original Abstract
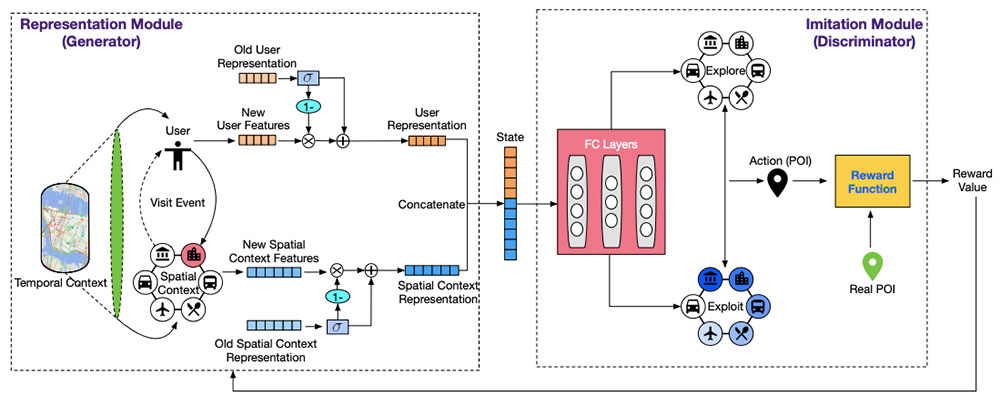
In this paper, we study the problem of mobile user profiling, which is a critical component for quantifying users’ characteristics in the human mobility modeling pipeline. Human mobility is a sequential decision-making process dependent on the users’ dynamic interests. With accurate user profiles, the predictive model can perfectly reproduce users’ mobility trajectories. In the reverse direction, once the predictive model can imitate users’ mobility patterns, the learned user profiles are also optimal. Such intuition motivates us to propose an imitation-based mobile user profiling framework by exploiting reinforcement learning, in which the agent is trained to precisely imitate users’ mobility patterns for optimal user profiles. Specifically, the proposed framework includes two modules: (1) representation module, which produces state combining user profiles and spatio-temporal context in real-time; (2) imitation module, where Deep Q-network (DQN) imitates the user behavior (action) based on the state that is produced by the representation module. However, there are two challenges in running the framework effectively. First, epsilon-greedy strategy in DQN makes use of the exploration-exploitation trade-off by randomly pick actions with the epsilon probability. Such randomness feeds back to the representation module, causing the learned user profiles unstable. To solve the problem, we propose an adversarial training strategy to guarantee the robustness of the representation module. Second, the representation module updates users’ profiles in an incremental manner, requiring integrating the temporal effects of user profiles. Inspired by Long-short Term Memory (LSTM), we introduce a gated mechanism to incorporate new and old user characteristics into the user profile.
Our Summary
Better mobile user profiling that could accurately predict where a user goes next would help in better personalization of virtual assistant features and ads for relevant services, among other use cases. Modeling user behavior from past data and achieving mobile user profiling presents a lot of challenges, including the dynamic interests of users changing over time and the difficulty of modeling the spatio-temporal context of mobility in real time. This work addresses the problem of mobile user profiling by building a reinforcement learning (RL)-powered agent that could imitate a user’s decisions, i.e., predict their next steps accurately. The authors achieved accurate mobile user profiling by accurately predicting user behavior because, as accurate user profiling predicts the future behavior of the user, accurate prediction of future behavior of the user also achieves accurate mobile profiling. The proposed method achieves superior results compared to existing methods on two large-scale real-world datasets collected from New York and Beijing.
What’s the core idea of this paper?
- To predict future user behavior, the authors introduce a RL-powered imitation learning method termed Reinforcement Imitative Representation Learning (RIRL). Imitation learning is achieved using adversarial training where a generator, the imitating agent, predicts the user behavior and a discriminator tries to learn to distinguish which behavior is predicted by the generator and which is from the real-world data. The imitating agent predicts the future user behavior accurately after the generator and discriminator are trained.
- Graph neural networks are used to represent the spatio-temporal nature of mobile user behavior, which is better than encoding it as a sequence or just a list of visited places.
- A Long Short-Term Memory (LSTM)-inspired RNN variant is devised and used to model the dynamic nature of user interests with a gating mechanism to retain only the relevant information from the past. The state vector for the RL imitation agent is generated with representations from this RNN variant and graph neural networks.
What’s the key achievement?
- Better mobile user profiling by predicting future user behavior using an RL-powered imitation agent trained adversarially.
- Better results than existing methods on multiple real-world datasets.
What are possible business applications?
- Accurately predicting where a person will go next opens up an interesting set of business applications like:
- recommending offers, restaurants, or services based on the location;
- better personalized virtual assistant features;
- automation of useful tasks through IoT devices at home just before the user comes home.
Enjoy this article? Sign up for more AI research updates.
We’ll let you know when we release more summary articles like this one.
Leave a Reply
You must be logged in to post a comment.